Add arbitrary Stan code to an HBOMS model¶
One goal of HBOMS is to produce human-readable Stan models that can be further developed and customized by the user. However, modifying an HBOMS-generated model makes it hard to change the basic parameter structure, as the modifications would have to be re-applied after each change. Therefore, the user can also include “plugin” Stan code in the HBOMS model definition. This plugin code is added as-is at the end of the code blocks (or beginning for the functions block).
To use this functionality, the user must provide a Python dictionary with keys equal to the names of the code blocks. For example
plugin_code = {
"data" : "real SomeDataPoint;",
"model" : "SomeDataPoint ~ exponential(lambda);"
}
will add the declaration for SomeDataPoint to the data block, and a “sampling statement” to the model block. This sampling statement uses a parameter lambda and so it is important that this is defined in the HBOMS model.
The plugin_code dictionary is then passed as a keyword argument in the HbomsModel initiation
model = hboms.HbomsModel(
name = "my_model",
# other arguments...
plugin_code = plugin_code
)
Example: SEIR model with serial interval data¶
As an example, we look at an epidemiological model of an infectious disease in which we have time series data, but also additional observations in the form of observed serial intervals (the time between symptom onset of a primary and secondary patient). The epidemiological model will be the SEIR model (susceptible, exposed, infected, recovered), and we will pretend that the serial interval is the same as the generation interval (the time between infections).
The ODEs for the SEIR model are given by
and initial condition \(S(0) = 1-\epsilon\), \(E(0) = 0\), \(I(0) = \epsilon\).
We’ll assument that the observed data at time t follows a Poisson distribution with mean SampleSize * I(t).
Let’s start with creating the nessecary ingredients of an HBOMS model.
import hboms
params = [
hboms.Parameter("beta", 1.0, "random", scale=0.1),
hboms.Parameter("alpha", 1.0, "random", scale=0.1),
hboms.Parameter("gamma", 0.5, "random", scale=0.1),
hboms.Parameter("SampleSize", 1e2, "const")
]
init = """
S_0 = 0.998;
E_0 = 0.0;
I_0 = 0.002; // we're lazy and use a hard-coded epsilon
"""
odes = """
ddt_S = -beta * S * I;
ddt_E = beta * S * I - alpha * E;
ddt_I = alpha * E - gamma * I;
"""
state = [hboms.Variable("S"), hboms.Variable("E"), hboms.Variable("I")]
obs = [hboms.Observation("Counts", data_type="int")]
dists = [hboms.StanDist("poisson", "Counts", ["I * SampleSize"])]
As additional data, we have a number of observed generation intervals \(T_G\) which in the SEIR model are hypoexponentially distributed with rate parameters \(\alpha\) and \(\beta\). A hypoexponential random variable is the sum of two exponentially distributed random variables. Hence it is like the Erlang distribution, but the rates can differ between the summands. In e.g. Roberts and Heesterbeek, we find an explicit formula for the PDF
This equation is a bit annoying for estimating \(\alpha\) and \(\gamma\), though, because it has a removable singularity at \(\alpha = \gamma\). Therefore, we use a somewhat less explicit, but equivalent, equation
and \(\exp\) is the matrix exponential and we trust that the implementation of the matrix exponential in Stan is efficient and accurate.
To implement this, we will add some plugin code to the functions, data and model blocks.
We define the hypoexp distribution in the functions block, declare a data array (and it’s size) in the data block and write a “sampling statement” for the model block. For defining the data array, we can make use of the variable R which is the number of units.
For the sampling statements, we’ll make use of the parameters \(\alpha\) and \(\gamma\).
Caution
As these are random parameters, we will have to index them. If you were to change \(\alpha\) or \(\gamma\) to fixed parameters, you would have to make sure the indexing is removed in the plugin code.
With this plugin code in place, we finally initiate the HBOMS model.
plugin_code_functions = """
real hypoexp_lpdf(real t, real a, real b) {
matrix[2, 2] Theta = [[-a, a], [0,-b]];
return log(sum((-matrix_exp(Theta .* t) * Theta)[1,:]));
}
"""
plugin_code_data = """
int NumIntervalSamples;
array[R, NumIntervalSamples] real IntervalSamples;
"""
plugin_code_model = """
for ( r in 1:R ) {
for ( n in 1:NumIntervalSamples ) {
IntervalSamples[r,n] ~ hypoexp(alpha[r], gamma[r]);
}
}
"""
plugin_code = {
"functions" : plugin_code_functions,
"data" : plugin_code_data,
"model" : plugin_code_model
}
model = hboms.HbomsModel(
"plugin_model",
state,
odes,
init,
params,
obs,
dists,
plugin_code=plugin_code
)
Using the show_stan_model utility, we can have a look at what HBOMS has generated.
Notice that the plugin function is defined before the other functions. The motivation is that we might want to define functions that are used in the ODE model definition. The other plugin code is added at the end of the code blocks.
hboms.utilities.show_stan_model(model.model_code)
functions {
/* User-provided plugin code */
real hypoexp_lpdf(real t, real a, real b) {
matrix[2, 2] Theta = [[-a, a], [0,-b]];
return log(sum((-matrix_exp(Theta .* t) * Theta)[1,:]));
}
/* vector field */
vector ode_fun(real t, vector state, real beta, real alpha, real gamma) {
/* unpack the state variables */
real S = state[1];
real E = state[2];
real I = state[3];
/* declare derivatives of state variables */
real ddt_S, ddt_E, ddt_I;
/* user-defined ODEs */
ddt_S = -beta * S * I;
ddt_E = beta * S * I - alpha * E;
ddt_I = alpha * E - gamma * I;
/* return literal vector with derivatives */
return [ddt_S, ddt_E, ddt_I]';
}
/* initial condition */
vector gen_init() {
/* declare initial variables */
real S_0, E_0, I_0;
/* user-defined initial condition */
S_0 = 0.998;
E_0 = 0.0;
I_0 = 0.002;
/* return literal vector with initival state variables */
return [S_0, E_0, I_0]';
}
/* IVP solver function */
array[] vector solve_ivp(data array[] real Time, real beta, real alpha, real gamma) {
int N = num_elements(Time); /* number of time points */
vector[3] init_state = gen_init(); /* generate initial state */
array[N] vector[3] sol; /* allocate space for solution */
sol[1:N, 1:3] = ode_rk45(ode_fun, init_state, 0.0, Time[1:N], beta, alpha, gamma); /* solve initial value problem */
return sol; /* return the solution */
}
/* auxiliary function for map_rect */
vector map_rect_helper_fun(vector ppar, vector upar, data array[] real rdat, data array[] int idat) {
int N = idat[1]; /* number of time points */
/* solve initial value problem */
array[N] vector[3] sol = solve_ivp(rdat[1:N + 0], upar[1], upar[2], upar[3]);
/* concatenate solution into a vector */
vector[3 * N] res;
for ( n in 1:N ) res[(n - 1) * 3 + 1:n * 3] = sol[n];
return res;
}
/* log-likelihood function */
vector loglik_fun(int Counts, vector state, data real SampleSize) {
/* unpack required state variables */
real I = state[3];
/* declare log-lik variables */
real ll_Counts = 0.0;
/* user-defined log-likelihood */
ll_Counts = poisson_lpmf(Counts | I * SampleSize); /* poisson log-likelihood */
return [ll_Counts]';
}
/* rng function */
int Counts_rng(vector state, data real SampleSize) {
/* unpack required state variables */
real I = state[3];
/* declare variable to-be-returned */
int Counts;
/* user-defined sampler */
Counts = poisson_rng(I * SampleSize); /* random poisson sample */
return Counts;
}
}
data {
int<lower=0> R; /* number of units */
array[R] int<lower=0> N; /* number of observations per unit */
array[R, max(N)] real<lower=0.0> Time; /* observation times */
/* observations */
array[R, max(N)] int Counts;
int<lower=0> NSim; /* number of simulation time points */
array[R, NSim] real<lower=0.0> TimeSim; /* simulation time points */
/* constants */
real<lower=0.0> SampleSize;
/* User-provided plugin code */
int NumIntervalSamples;
array[R, NumIntervalSamples] real IntervalSamples;
}
transformed data {
/* declarations */
array[R, max(N)] real rdats;
array[R, 1] int idats; /* integer data */
/* definitions */
rdats[:, 1:max(N)] = Time;
idats[:, 1] = N;
}
parameters {
/* individual parameters (and their hyper-parameters) */
array[R] real<lower=0.0> beta;
real loc_beta;
real<lower=0.0> scale_beta;
array[R] real<lower=0.0> alpha;
real loc_alpha;
real<lower=0.0> scale_alpha;
array[R] real<lower=0.0> gamma;
real loc_gamma;
real<lower=0.0> scale_gamma;
}
transformed parameters {
array[R] vector[3] upars; /* prepare data structure for map_rect */
vector[0] ppar; /* no population parameters required for map_rect */
/* assign unit-parameters to array of vectors */
upars[:, 1] = beta;
upars[:, 2] = alpha;
upars[:, 3] = gamma;
}
model {
/* solve ODEs in parallel */
vector[sum(N) * 3] concat_res = map_rect(map_rect_helper_fun, ppar, upars, rdats, idats);
/* compute log-likelihood of observations */
for ( r in 1:R ) {
for ( n in 1:N[r] ) {
/* extract state */
int idx = 3 * (sum(N[:r - 1]) + n - 1) + 1;
vector[3] state = concat_res[idx:idx + 2];
/* compute likelihood of observation given state */
target += loglik_fun(Counts[r, n], state, SampleSize);
}
}
/* prior */
beta ~ lognormal(loc_beta, scale_beta);
loc_beta ~ student_t(3.0, 0.0, 2.5);
scale_beta ~ student_t(3.0, 0.0, 2.5);
alpha ~ lognormal(loc_alpha, scale_alpha);
loc_alpha ~ student_t(3.0, 0.0, 2.5);
scale_alpha ~ student_t(3.0, 0.0, 2.5);
gamma ~ lognormal(loc_gamma, scale_gamma);
loc_gamma ~ student_t(3.0, 0.0, 2.5);
scale_gamma ~ student_t(3.0, 0.0, 2.5);
/* User-provided plugin code */
for ( r in 1:R ) {
for ( n in 1:NumIntervalSamples ) {
IntervalSamples[r,n] ~ hypoexp(alpha[r], gamma[r]);
}
}
}
generated quantities {
array[R, NSim] real S_sim, E_sim, I_sim;
array[R, max(N)] int Counts_sim;
vector[sum(N) * 1] log_lik; /* vector of log-likelihoods for model comparison */
for ( r in 1:R ) {
array[NSim] vector[3] u_sim = solve_ivp(TimeSim[r], beta[r], alpha[r], gamma[r]); /* solve ODEs at simulation times */
array[N[r]] vector[3] u_sim_obs = solve_ivp(Time[r, 1:N[r]], beta[r], alpha[r], gamma[r]); /* solve ODEs at observation times */
for ( n in 1:NSim ) {
S_sim[r, n] = u_sim[n, 1];
E_sim[r, n] = u_sim[n, 2];
I_sim[r, n] = u_sim[n, 3];
}
for ( n in 1:N[r] ) {
int idx = 1 * (sum(N[:r - 1]) + n - 1) + 1;
log_lik[idx:idx + 0] = loglik_fun(Counts[r, n], u_sim_obs[n], SampleSize); /* record log-likelihood of each observation */
Counts_sim[r, n] = Counts_rng(u_sim_obs[n], SampleSize); /* simulate data at observation times */
}
}
}
Simulate data with the Stan model¶
Next, we use the Stan model to simulate some data. We have to provide time points for each unit at which we want to generate pseudo-observations.
import numpy as np
R = 6
Time = [np.linspace(1, 40, 40) for _ in range(R)]
data = {"Time" : Time}
sims = model.simulate(data=data, num_simulations=10)
# select the first simulated data set, and get the random parameters
sim_data, sim_pars = sims[0]
15:05:34 - cmdstanpy - INFO - CmdStan start processing
15:05:34 - cmdstanpy - INFO - Chain [1] start processing
15:05:34 - cmdstanpy - INFO - Chain [1] done processing
We will now add simulated generation intervals for each unit. We can simulate these using the sum of two exponentially distributed random deviates, using scipy.stats.
import scipy.stats as sts
alpha_gt = sim_pars["alpha"]
gamma_gt = sim_pars["gamma"]
NumIntervalSamples = 100
IntervalSamples = [
sts.expon.rvs(scale=1/alpha, size=NumIntervalSamples) + \
sts.expon.rvs(scale=1/gamma, size=NumIntervalSamples)
for alpha, gamma in zip(alpha_gt, gamma_gt)
]
sim_data["NumIntervalSamples"] = NumIntervalSamples
sim_data["IntervalSamples"] = IntervalSamples
Fit the Stan model to the simulated data¶
Next, we use the sample method to fit the model. At this point it is important that the additinal data has been added to the data dictionary sim_data, otherwise Stan will raise an exception, indicating that data is missing. This is also true if you use init_check.
model.sample(
data=sim_data,
iter_warmup=200, iter_sampling=200,
refresh=1,
step_size=0.01, adapt_delta=0.95,
threads_per_chain=R
)
15:05:34 - cmdstanpy - INFO - CmdStan start processing
15:09:01 - cmdstanpy - INFO - CmdStan done processing.
15:09:01 - cmdstanpy - WARNING - Some chains may have failed to converge.
Chain 1 had 3 divergent transitions (1.5%)
Chain 2 had 1 divergent transitions (0.5%)
Chain 4 had 5 divergent transitions (2.5%)
Use the "diagnose()" method on the CmdStanMCMC object to see further information.
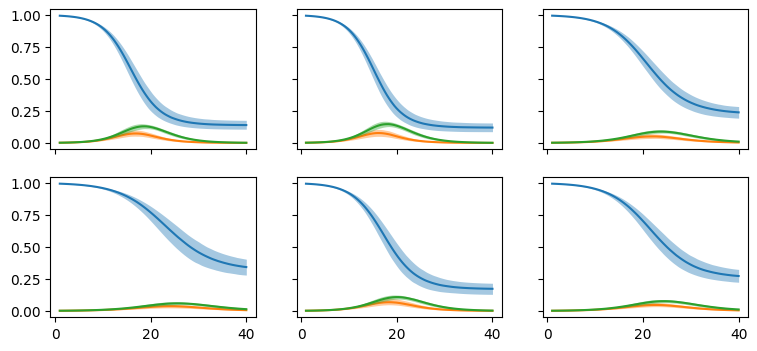
We then use post_pred_check to inspect the fitted model trajectories.
fig = model.post_pred_check(data=sim_data, obs_names=[])
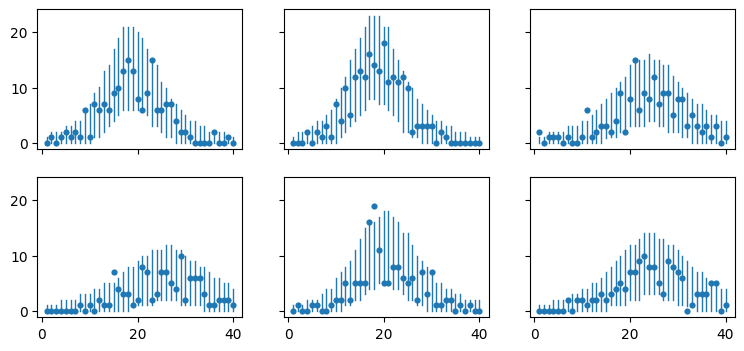
And how the posterior predictive distributions mach with the data.
fig = model.post_pred_check(data=sim_data, state_var_names=[])
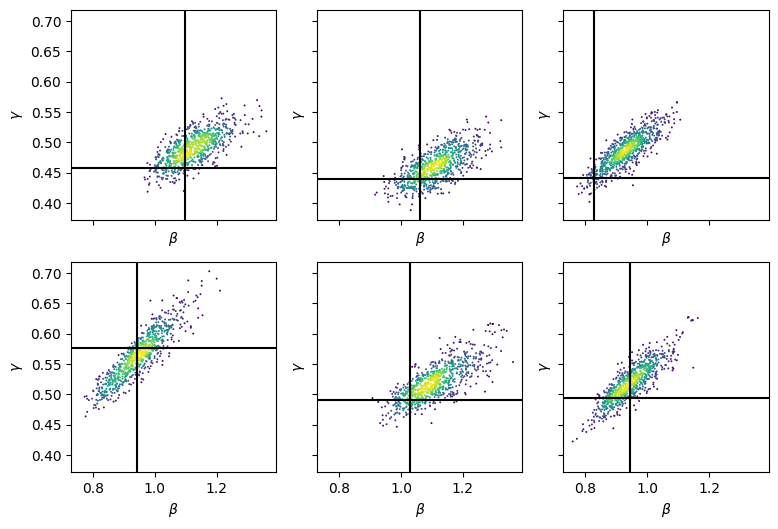
Even though we have a lot of data to infer parameter values from, the parameters show high posterior correlations. We show this for \(\beta\) and \(\gamma\) below
import matplotlib.pyplot as plt
def plot_beta_vs_gamma(model, gt_pars, nrows, ncols):
fig, axs = plt.subplots(nrows, ncols, figsize=(3*ncols,3*nrows), sharex=True, sharey=True)
for i, ax in enumerate(axs.flat):
beta = model.fit.stan_variable("beta")[:,i]
gamma = model.fit.stan_variable("gamma")[:,i]
z = sts.gaussian_kde(bg := np.stack([beta, gamma]))(bg)
ax.scatter(beta, gamma, s=2, linewidths=0, c=z)
ax.set(xlabel="$\\beta$", ylabel="$\\gamma$")
beta_gt = gt_pars["beta"][i]
gamma_gt = gt_pars["gamma"][i]
ax.axhline(gamma_gt, color='k')
ax.axvline(beta_gt, color='k')
return fig, axs
fig, axs = plot_beta_vs_gamma(model, sim_pars, 2, 3)
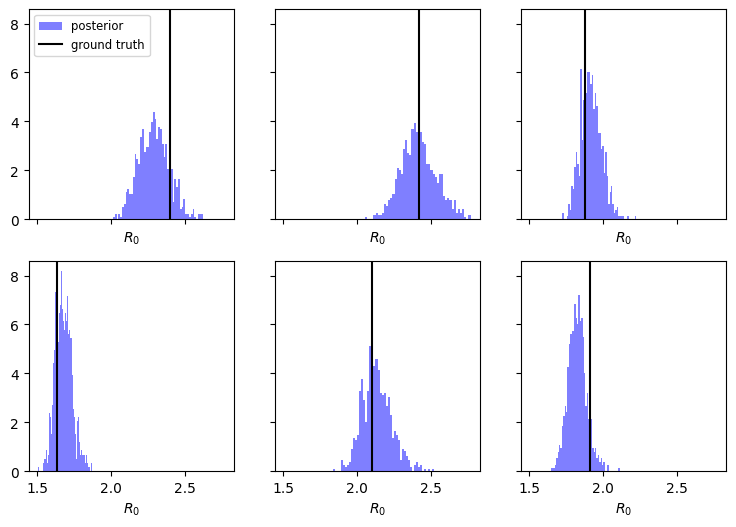
Of course we can also estimate the basic reproduction number \(R_0 = \beta / \gamma\). We can quite precisely estimate \(R_0\), which would not be the case had we excluded the generation interval data.
def plot_R0(model, gt_pars, nrows, ncols):
R0 = model.fit.stan_variable("beta") / model.fit.stan_variable("gamma")
R0_gt = gt_pars["beta"] / gt_pars["gamma"]
fig, axs = plt.subplots(nrows, ncols, figsize=(3*ncols,3*nrows), sharex=True, sharey=True)
for i, ax in enumerate(axs.flat):
ax.hist(R0[:,i], 50, density=True, color='b', alpha=0.5, label="posterior")
ax.axvline(R0_gt[i], color='k', label="ground truth")
ax.set_xlabel("$R_0$")
axs.flat[0].legend(fontsize='small')
return fig, axs
fig, axs = plot_R0(model, sim_pars, 2, 3)